Kafka高频面试题
Kafka高频面试题
1、请说明什么是Apache Kafka?
Apache Kafka是由Apache开发的一种发布订阅消息系统,它是一
个分布式的、分区的和可复制的提交日志服务。
2、说说Kafka的使用场景?
①异步处理
②应用解耦
③流量削峰
④日志处理
⑤消息通讯等。
3、使用Kafka有什么优点和缺点?
优点:
①支持跨数据中心的消息复制;
②单机吞吐量:十万级,最大的优点,就是吞吐量高;
③topic数量都吞吐量的影响:topic从几十个到几百个的时候,吞吐
量会大幅度下降。所以在同等机器下,kafka尽量保证topic数量不
要过多。如果要支撑大规模topic,需要增加更多的机器资源;
④时效性:ms级;
⑤可用性:非常高,kafka是分布式的,一个数据多个副本,少数机
器宕机,不会丢失数据,不会导致不可用;
⑥消息可靠性:经过参数优化配置,消息可以做到0丢失;
⑦功能支持:功能较为简单,主要支持简单的MQ功能,在大数据
领域的实时计算以及日志采集被大规模使用。
缺点:
①由于是批量发送,数据并非真正的实时; 仅支持统一分区内消息
有序,无法实现全局消息有序;
②有可能消息重复消费;
③依赖zookeeper进行元数据管理,等等。
4、为什么说Kafka性能很好,体现在哪里?
①顺序读写
②零拷贝
③分区
④批量发送
⑤数据压缩
5、请说明什么是传统的消息传递方法?
传统的消息传递方法包括两种:
排队:在队列中,一组用户可以从服务器中读取消息,每条消息都发送给其中一个人。
发布-订阅:在这个模型中,消息被广播给所有的用户。
6、请说明Kafka相对传统技术有什么优势?
①快速:单一的Kafka代理可以处理成千上万的客户端,每秒处理数兆字节的读写操作。
②可伸缩:在一组机器上对数据进行分区<和简化,以支持更大的数据
③持久:消息是持久性的,并在集群中进行复制,以防止数据丢失。
④设计:它提供了容错保证和持久性
7、解释Kafka的Zookeeper是什么?我们可以在没有Zookeeper的情况下使用Kafka吗?
Zookeeper是一个开放源码的、高性能的协调服务,它用于Kafka的分布式应用。
不,不可能越过Zookeeper,直接联系Kafka broker。一旦Zookeeper停止工作,它就不能服务客户端请求。
Zookeeper主要用于在集群中不同节点之间进行通信在Kafka中,它被用于提交偏移量,因此如果节点在任何情况下都失败了,它都可以从之前提交的偏移量中获取
除此之外,它还执行其他活动,如: leader检测、分布式同步、配置管理、识别新节点何时离开或连接、集群、节点实时状态等等。
8、解释Kafka的用户如何消费信息?
在Kafka中传递消息是通过使用sendfile API完成的。它支持将字节
从套接口转移到磁盘,通过内核空间保存副本,并在内核用户之间
调用内核。
9、解释如何提高远程用户的吞吐量?
如果用户位于与broker不同的数据中心,则可能需要调优套接口缓
冲区大小,以对长网络延迟进行摊销。
10、解释一下,在数据制作过程中,你如何能从Kafka得到准确的信息?
在数据中,为了精确地获得Kafka的消息,你必须遵循两件事: 在数
据消耗期间避免重复,在数据生产过程中避免重复。
这里有两种方法,可以在数据生成时准确地获得一个语义:
每个分区使用一个单独的写入器,每当你发现一个网络错误,检查
该分区中的最后一条消息,以查看您的最后一次写入是否成功
在消息中包含一个主键(UUID或其他),并在用户中进行反复制
11、解释如何减少ISR中的扰动?broker什么时候离开ISR?
ISR是一组与leaders完全同步的消息副本,也就是说ISR中包含了所
有提交的消息。ISR应该总是包含所有的副本,直到出现真正的故
障。如果一个副本从leader中脱离出来,将会从ISR中删除。
12、Kafka为什么需要复制?
Kafka的信息复制确保了任何已发布的消息不会丢失,并且可以在机
器错误、程序错误或更常见些的软件升级中使用。
13、如果副本在ISR中停留了很长时间表明什么?
如果一个副本在ISR中保留了很长一段时间,那么它就表明,跟踪器
无法像在leader收集数据那样快速地获取数据。
14、请说明如果首选的副本不在ISR中会发生什么?
如果首选的副本不在ISR中,控制器将无法将leadership转移到首选
的副本。
15、有可能在生产后发生消息偏移吗?
在大多数队列系统中,作为生产者的类无法做到这一点,它的作用
是触发并忘记消息。broker将完成剩下的工作,比如使用id进行适
当的元数据处理、偏移量等。
作为消息的用户,你可以从Kafka broker中获得补偿。如果你注视SimpleConsumer类,你会注意到它会获取包括偏移量作为列表的MultiFetchResponse对象。此外,当你对Kafka消息进行迭代时,你会拥有包括偏移量和消息发送的MessageAndOffset对象。
16、Kafka的设计时什么样的呢?
Kafka将消息以topic为单位进行归纳
将向Kafka topic发布消息的程序成为producers. 将预订topics并消费消息的程序成为consumer.
Kafka以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker.
producers通过网络将消息发送到Kafka集群,集群向消费者提供消息
17、数据传输的事物定义有哪三种?
(1)最多一次:消息不会被重复发送,最多被传输一次,但也有可能一次不传输
(2)最少一次: 消息不会被漏发送,最少被传输一次,但也有可能被重复传输.
(3)精确的一次(Exactly once): 不会漏传输也不会重复传输,每个消息都传输被一次而且仅仅被传输一次,这是大家所期望的
18、Kafka判断一个节点是否还活着有那两个条件?
(1)节点必须可以维护和ZooKeeper的连接,Zookeeper通过心跳机制检查每个节点的连接
(2)如果节点是个follower,他必须能及时的同步leader的写操作,延时不能太久
19、producer是否直接将数据发送到broker的leader(主节点)?
producer直接将数据发送到broker的leader(主节点),不需要在多个节点进行分发,为了帮助producer做到这点,所有的Kafka节点都可以及时的告知:哪些节点是活动的,目标topic目标分区的leader在哪。这样producer就可以直接将消息发送到目的地了。
20、Kafa consumer是否可以消费指定分区消息?
Kafa consumer消费消息时,向broker发出"fetch"请求去消费特定分区的消息,consumer指定消息在日志中的偏移量(offset),就可以消费从这个位置开始的消息,customer拥有了offset的控制权,可以向后回滚去重新消费之前的消息,这是很有意义的
21、Kafka消息是采用Pull模式,还是Push模式?
Kafka最初考虑的问题是,customer应该从brokes拉取消息还是
brokers将消息推送到consumer,也就是pull还push。在这方面,
Kafka遵循了一种大部分消息系统共同的传统的设计:producer将
消息推送到broker,consumer从broker拉取消息一些消息系统比
如Scribe和Apache
Flume采用了push模式,将消息推送到下游的consumer。这样做
有好处也有坏处:由broker决定消息推送的速率,对于不同消费速
率的consumer就不太好处理了。消息系统都致力于让consumer以
最大的速率最快速的消费消息,但不幸的是,push模式下,当
broker推送的速率远大于consumer消费的速率时,consumer恐怕
就要崩溃了。最终Kafka还是选取了传统的pull模式
Pull模式的另外一个好处是consumer可以自主决定是否批量的从
broker拉取数据。Push模式必须在不知道下游consumer消费能力
和消费策略的情况下决定是立即推送每条消息还是缓存之后批量推
送。如果为了避免consumer崩溃而采用较低的推送速率,将可能
导致一次只推送较少的消息而造成浪费。Pull模式下,consumer就
可以根据自己的消费能力去决定这些策略
Pull有个缺点是,如果broker没有可供消费的消息,将导致
consumer不断在循环中轮询,直到新消息到t达。为了避免这点,
Kafka有个参数可以让consumer阻塞知道新消息到达(当然也可以阻
塞知道消息的数量达到某个特定的量这样就可以批量发)
22、Kafka存储在硬盘上的消息格式是什么?
消息由一个固定长度的头部和可变长度的字节数组组成。头部包含了一个版本号和CRC32校验码。
消息长度: 4 bytes (value: 1+4+n)
版本号: 1 byte
CRC校验码: 4 bytes
具体的消息: n bytes
23、Kafka高效文件存储设计特点:
(1).Kafka把topic中一个parition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。
(2).通过索引信息可以快速定位message和确定response的最大大小。
(3).通过index元数据全部映射到memory,可以避免segment file的IO磁盘操作。
(4).通过索引文件稀疏存储,可以大幅降低index文件元数据占用空间大小。
24、Kafka 与传统消息系统之间有三个关键区别
(1).Kafka 持久化日志,这些日志可以被重复读取和无限期保留
(2).Kafka 是一个分布式系统:它以集群的方式运行,可以灵活伸缩,在内部通过复制数据提升容错能力和
(3).Kafka 支持实时的流式处理
25、Kafka创建Topic时如何将分区放置到不同的Broker中
副本因子不能大于 Broker 的个数;
第一个分区(编号为0)的第一个副本放置位置是随机从brokerList 选择的;
其他分区的第一个副本放置位置相对于第0个分区依次往后移。也就是如果我们有5个
Broker,5个分区,假设第一个分区放在第四个 Broker 上,那么第二个分区将会放在第五个 Broker 上;第三个分区将会放在第一个
Broker 上;第四个分区将会放在第二个 Broker 上,依次类推;剩余的副本相对于第一个副本放置位置其实是由 nextReplicaShift决定的,而这个数也是随机产生的
26、Kafka新建的分区会在哪个目录下创建
在启动Kafka 集群之前,我们需要配置好 log.dirs 参数,其值是 Kafka
数据的存放目录,这个参数可以配置多个目录,目录之间使用逗号
分隔,通常这些目录是分布在不同的磁盘上用于提高读写性能。 当
然我们也可以配置
log.dir 参数,含义一样。只需要设置其中一个即可。 如果 log.dirs
参数只配置了一个目录,那么分配到各个 Br
上的分区肯定只能在这个目录下创建文件夹用于存放数据。 但是如
果 log.dirs 参数配置了多个目录,那么 Kafka
会在哪个文件夹中创建分区目录呢?答案是:Kafka 会在含有分区
目录最少的文件夹中创建新的分区目录,分区目录名为
Topic名+分区ID。注意,是分区文件夹总数最少的目录,而不是磁
盘使用量最少的目录!也就是说,如果你给 log.dirs
参数新增了一个新的磁盘,新的分区目录肯定是先在这个新的磁盘
上创建直到这个新的磁盘目录拥有的分区目录不是最少为止。
27、partition的数据如何保存到硬盘
topic中的多个partition以文件夹的形式保存到broker,每个分区序号从0递增,
且消息有序 Partition文件下有多个segment(xxx.index,xxx.log) segment 文件里的大小和配置文件大小一致可以根据要求修改 默认为1g如果大小大于1g时,会滚动一个新的segment并且以上一个segment最后一条消息的偏移量命名
28、kafka的ack机制
request.required.acks有三个值 0 1 -1
0:生产者不会等待broker的ack,这个延迟最低但是存储的保证最弱
当server挂掉的时候就会丢数据
1:服务端会等待ack值 leader副本确认接收到消息后发送ack但是
如果leader挂掉后他不确保是否复制完成新leader也会导致数据丢
失
-1:同样在1的基础上 服务端会等所有的follower的副本受到数据后
才会受到leader发出的ack,这样数据不会丢失
29、Kafka的消费者如何消费数据
消费者每次消费数据的时候,消费者都会记录消费的物理偏移量
(offset)的位置 等到下次消费时,他会接着上次位置继续消费。
同时也可以按照指定的offset进行重新消费。
30、消费者负载均衡策略
结合consumer的加入和退出进行再平衡策略。
31、kafka消息数据是否有序?
消费者组里某具体分区是有序的,所以要保证有序只能建一个分
区,但是实际这样会存在性能问题,具体业务具体分析后确认。
32、kafaka生产数据时数据的分组策略,生产者决定数据产生到集群的哪个partition中
每一条消息都是以(key,value)格式 Key是由生产者发送数据传
入 所以生产者(key)决定了数据产生到集群的哪个partition
33、kafka consumer 什么情况会触发再平衡reblance?
①一旦消费者加入或退出消费组,导致消费组成员列表发生变化,消费组中的所有消费者都要执行再平衡。
②订阅主题分区发生变化,所有消费者也都要再平衡。
34、描述下kafka consumer 再平衡步骤?
①关闭数据拉取线程,情空队列和消息流,提交偏移量;
②释放分区所有权,删除zk中分区和消费者的所有者关系;
③将所有分区重新分配给每个消费者,每个消费者都会分到不同分区;
④将分区对应的消费者所有关系写入ZK,记录分区的所有权信息;
⑤重启消费者拉取线程管理器,管理每个分区的拉取线程。
35消费者 consumer 是线程安全的吗?多线程实例、单线程实例、单consumer + 多 worker 线程的优缺点?
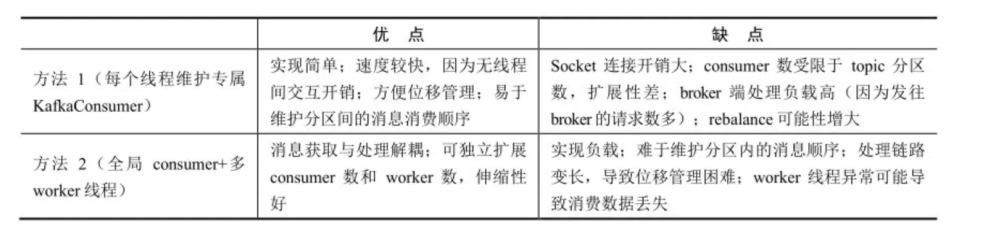
36消息拉取时,什么情况下会造成消息重复消费?谈谈你对位移提交的理解?
理解消息交付语义:
最多一次(atmostonce):消息可能丢失也可能被处理,但最多只会被处理一次;
至少一次(atleastonce):消息不会丢失,但可能被处理多次;
精确一次(exactlyonce):消息被处理且只会被处理一次。
假若消费者在消费前提交位移,那么就是“最多一次”,若在消费后
提交位移,那么就是“最少一次”,如果能够保证消费和提交位移同
在一个事务中执行,就可保证“精确一次”。__consumer_offsets
的一些理解。
37.Kafka 分区数越多性能就越好吗?为什么?
我的理解:
- 每个分区数都对应一个 log 文件,log 文件是顺序写的,但如果
有非常多分区同时刷盘,就会变相成乱序写了,我猜想这也是为
什么 RocketMQ 一个 broker 只会拥有一个 CommitLog 的原因
之一吧; - 客户端会为每个分区调用一条线程处理,多线程并发地处理分区
消息,分区越多,意味着处理的线程数也就越多,到一定程度
后,会造成线程切换开销大; - 其中一个 broker 挂掉后,如果此时分区特别多,Kafka 分区
leader 重新选举的时间大大增加; - 每个分区对应都有文件句柄,分区越多,系统文件句柄就越多;
- 客户端在会为每个分区分配一定的缓冲区,如果分区过多,分配
的内存也越大。
38、Kafka 如何保证消息不丢失?
生产者端:
- 设置
acks=all(或-1),确保消息被所有 ISR 副本确认后才返回成功 - 设置
retries > 0,启用重试机制 - 使用
enable.idempotence=true开启幂等性生产 - 配置
max.in.flight.requests.per.connection=1(幂等性开启时默认为 5)
Broker 端:
- 设置分区副本数
replication.factor >= 3 - 设置最小同步副本数
min.insync.replicas >= 2 - 禁用"不洁首领选举"
unclean.leader.election.enable=false
消费者端:
- 关闭自动提交位移
enable.auto.commit=false - 手动提交位移,确保消息处理完成后再提交
- 使用消费者组的位移管理机制
39、Kafka 如何保证消息顺序性?
Kafka 只能保证单分区内的消息有序性。要实现全局有序,需要以下策略:
- 将需要保证顺序的消息发送到同一个分区(通过指定相同的 Key)
- 生产者设置
max.in.flight.requests.per.connection=1,确保发送顺序 - 如果一个 Topic 只有一个分区,则天然全局有序,但会丧失并行处理能力
实际生产中,通常将需要顺序的消息通过相同的业务 Key(如订单 ID)路由到同一分区,保证相关消息的局部有序即可。
40、Kafka 的 ISR 机制是什么?
ISR(In-Sync Replicas)是与 Leader 副本保持同步的副本集合。
- Leader 负责处理所有读写请求
- Follower 定期从 Leader 拉取数据保持同步
- 只有 ISR 中的副本才有资格被选为新 Leader
min.insync.replicas控制写入时至少需要多少个 ISR 副本确认
OSR(Out-of-Sync Replicas)是落后太多的副本。ISR 和 OSR 合在一起就是 AR(All Replicas)。
41、Kafka 如何处理消息积压?
消息积压是 Kafka 生产环境的常见问题,处理方案:
- 紧急扩容:增加消费者数量(不能超过分区数)或增加分区数
- 临时消费者:编写专门的消息处理程序,只做转发或归档
- 跳过非关键消息:临时调整消费逻辑,快速消费积压
- 增加消费者线程:在每个消费者内部增加处理线程数
- 优化消费逻辑:检查是否有慢查询、外部调用超时等问题
预防措施:
- 监控消费者 lag,设置告警阈值
- 合理设置分区数,预留扩容空间
- 消费端做幂等处理,支持重复消费
42、Kafka 与 RabbitMQ 的区别?
| 对比项 | Kafka | RabbitMQ |
|---|---|---|
| 设计目标 | 高吞吐日志流 | 企业消息中间件 |
| 吞吐量 | 十万级/秒 | 万级/秒 |
| 延迟 | ms 级 | us 级 |
| 消息保留 | 持久化到磁盘,可回溯 | 消费后删除 |
| 消费模型 | Pull(拉取) | Push(推送) |
| 有序性 | 分区内有序 | 队列内有序 |
| 事务支持 | 支持( Exactly Once) | 不支持分布式事务 |
| 适用场景 | 日志采集、流处理、大数据 | 业务消息、任务队列、RPC |
43、Kafka 的零拷贝原理?
零拷贝(Zero-Copy)是 Kafka 高性能的关键技术之一:
- 传统数据传输:磁盘 -> 内核缓冲区 -> 用户缓冲区 -> Socket 缓冲区 -> 网卡(4 次拷贝,4 次上下文切换)
- sendfile 零拷贝:磁盘 -> 内核缓冲区 -> 网卡(2 次拷贝,2 次上下文切换)
- Kafka 消费者使用
sendfile系统调用直接将磁盘数据通过 DMA 传输到网卡,跳过了用户空间的拷贝 - 配合页缓存(Page Cache),Kafka 还利用操作系统的文件缓存机制进一步减少磁盘 I/O
44、Kafka 生产者如何实现幂等性和事务?
幂等性(enable.idempotence=true):
- 每个 Producer 分配一个 PID(Producer ID)
- 每条消息带有一个 Sequence Number
- Broker 端维护
<PID, Partition, SeqNum>的映射 - 重复消息(相同 PID 和 SeqNum)会被自动过滤
事务(transactional.id):
- 支持跨多个分区和 Topic 的原子写入
- 配合
isolation.level=read_committed,消费者只读已提交的消息 - 事务流程:initTransactions -> beginTransaction -> send -> commitTransaction
- 适用场景:消费-处理-生产的"精确一次"语义
45、Kafka 控制器(Controller)的作用是什么?
Kafka Controller 是集群中的核心组件之一,负责管理集群状态:
- 分区 Leader 选举:当分区 Leader 宕机时,Controller 负责从 ISR 中选举新的 Leader
- 分区分配:创建 Topic 时,Controller 负责决定分区分配到哪些 Broker
- Broker 上下线管理:监听 ZooKeeper 中 Broker 节点的变化
- 副本管理:管理副本的创建、删除和重新分配
- 元数据管理:维护集群的元数据信息并广播给所有 Broker
集群中只有一个 Broker 会成为 Controller,通过在 ZooKeeper 中创建临时节点 /controller 来实现选举。
46、Kafka 日志段(Log Segment)的清理策略有哪些?
Kafka 提供两种日志清理策略,通过 log.cleanup.policy 配置:
delete(默认):基于时间或大小删除旧日志段
log.retention.hours=168:保留 7 天(默认)log.retention.bytes=-1:不限大小(默认)log.segment.bytes=1073741824:每个日志段最大 1GBlog.retention.check.interval.ms=300000:每 5 分钟检查一次
compact:基于 Key 压缩,保留每个 Key 最新的值
- 适用于状态变更、最新配置等场景
cleanup.policy=compactmin.cleanable.dirty.ratio=0.5:日志段中 50% 为过期数据时触发清理
- 适用于状态变更、最新配置等场景
47、Kafka 在 .NET 项目中的集成实践?
// 使用 Confluent.Kafka 库
// 1. 生产者配置
var producerConfig = new ProducerConfig
{
BootstrapServers = "localhost:9092",
Acks = Acks.All, // 等待所有 ISR 确认
EnableIdempotence = true, // 开启幂等
MessageSendMaxRetries = 3,
RetryBackoffMs = 500
};
// 2. 消费者配置
var consumerConfig = new ConsumerConfig
{
BootstrapServers = "localhost:9092",
GroupId = "order-service-group",
AutoOffsetReset = AutoOffsetReset.Earliest,
EnableAutoCommit = false, // 手动提交位移
MaxPollIntervalMs = 300000,
SessionTimeoutMs = 10000
};
// 3. 消费者手动提交位移
using var consumer = new ConsumerBuilder<string, string>(consumerConfig).Build();
consumer.Subscribe("order-events");
while (!cancellationToken.IsCancellationRequested)
{
var result = consumer.Consume(cancellationToken);
try
{
ProcessMessage(result.Message);
consumer.Commit(result); // 处理成功后手动提交
}
catch (Exception ex)
{
_logger.LogError(ex, "消息处理失败: {Topic} [{Partition}] @ {Offset}",
result.Topic, result.Partition, result.Offset);
// 不提交位移,下次消费会重新处理
}
}.NET 集成注意事项:
- 使用
EnableAutoCommit = false避免消息丢失 - 合理设置
MaxPollRecords避免单次拉取过多消息导致处理超时 - 消费者要做好幂等处理,防止重复消费导致数据不一致
- 使用 DI 容器管理 Kafka 生产者和消费者的生命周期
48、Kafka 中 ZooKeeper 的作用是什么?KRaft 模式是什么?
ZooKeeper 在 Kafka 中的传统作用包括:
- 存储 Broker 注册信息(哪个 Broker 存活)
- 存储 Topic 和 Partition 的元数据(分区分配、Leader 位置)
- Controller 选举(通过临时节点
/controller实现) - 存储消费者组的 Offset(旧版本,新版本已迁移到
__consumer_offsetsTopic) - ACL 权限管理
KRaft 模式(Kafka Raft Metadata Mode,Kafka 3.0+):
Kafka 社区为了消除对 ZooKeeper 的依赖,开发了 KRaft 模式。KRaft 使用 Kafka 内部的 Raft 共识协议来管理元数据,不再需要外部 ZooKeeper 集群。
KRaft 的优势:
- 简化运维:不再需要部署和维护独立的 ZooKeeper 集群
- 更快的元数据操作:元数据操作延迟从秒级降低到毫秒级
- 支持更大规模的集群:可以支持数百万个分区
- 更快的 Controller 故障转移
KRaft 的核心组件:KRaft Controller Quorum(通常 3 或 5 个节点),负责元数据的存储和一致性。Broker 作为 KRaft 的 follower 参与。
49、Kafka 事务是如何工作的?
Kafka 事务支持跨多个分区和 Topic 的原子写入,主要用于"消费-处理-生产"的精确一次语义。
事务流程:
- 初始化事务:
initTransactions() - 开启事务:
beginTransaction() - 发送消息到多个分区(这些消息带有事务标记)
- 提交事务:
commitTransaction()(所有消息对消费者可见) - 或者回滚事务:
abortTransaction()(所有消息被丢弃)
事务隔离级别:
read_uncommitted(默认):消费者可以读到未提交的消息read_committed:消费者只能读到已提交的消息
事务的应用场景:
- 消费一个 Topic 的消息,处理后写入另一个 Topic,保证原子性
- 跨多个分区的数据一致性保证
50、Kafka 监控的关键指标有哪些?
Broker 级别指标:
BytesInPerSec/BytesOutPerSec:入站/出站吞吐量MessagesInPerSec:消息入站速率RequestHandlerAvgIdlePercent:请求处理线程空闲率(低于 20% 需要扩容)UnderReplicatedPartitions:未充分复制的分区数(大于 0 表示有问题)OfflinePartitionsCount:离线分区数(大于 0 表示严重问题)ActiveControllerCount:集群中活跃的 Controller 数量(应该始终为 1)
Topic/Partition 级别指标:
- 消息积压(Consumer Lag):消费者落后于生产者的消息数量
- 分区大小(Log Size):过大的分区影响恢复时间
- 分区 Leader 分布:确保 Leader 均匀分布在各 Broker 上
Producer 级别指标:
record-send-rate:发送速率record-error-rate:发送错误率request-latency-avg:平均请求延迟record-queue-time-avg:消息在缓冲区等待时间
Consumer 级别指标:
records-lag-max:最大消息积压量records-consumed-rate:消费速率commit-latency-avg:提交位移的平均延迟
常用监控工具:Kafka Manager、Kafka Exporter + Prometheus + Grafana、Confluent Control Center。
这组题真正考什么
- 面试官往往不只是考定义,而是在看你能否把基础概念放回真实 .NET 场景。
- 这类题经常沿着语言基础、框架设计、性能和工程实践往下追问。
- 高分答案通常有三层:结论、原因、项目中的例子。
60 秒答题模板
- 先用一句话给结论。
- 再补关键原理或底层机制。
- 最后说适用边界、常见坑或项目中的使用经验。
容易失分的点
- 只会背术语,不会举例。
- 回答太散,没有结构。
- 忽略版本差异和工程背景。
刷题建议
- 把答案拆成“定义、适用场景、风险点、实战例子”四段来复述。
- 遇到 .NET 基础题时,尽量补一个框架级别的落地场景,而不是只背术语。
- 高频概念题建议自己再追问一层:底层原理、常见坑、性能代价分别是什么。
高频追问
- 如果面试官继续追问底层实现,你能否解释运行机制或源码层面的关键点?
- 如果题目放到 ASP.NET Core、消息队列或数据库场景里,这个结论是否还成立?
- 是否存在版本差异、框架差异或特殊边界条件需要主动说明?
复习重点
- 把每道题的关键词整理成自己的知识树,而不是只背原句。
- 对容易混淆的概念要做横向比较,例如机制差异、适用边界和性能代价。
- 复习时优先补“为什么”,其次才是“怎么用”和“记住什么术语”。
面试作答提醒
- 先给结论,再补原因和例子。
- 回答基础题时不要只说“能用”,最好补一句为什么这样选。
- 如果记不清细节,优先说出适用边界和排查思路。