Redis 6.x 持久化
Redis 6.x 持久化
Redis持久化机制
Redis对数据的操作都是基于内存的,当遇到了进程退出、服务器宕机等意外情况,如果没有持久化机
制,那么Redis中的数据将会丢失无法恢复。有了持久化机制,Redis在下次重启时可以利用之前持久化
的文件进行数据恢复。理解和掌握Redis的持久机制,对于Redis的日常开发和运维都有很大帮助。
Redis为持久化提供了两种方式:
- RDB:在指定的时间间隔能对你的数据进行快照存储。
- AOF:记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据。
接下来让大家更全面、清晰的认识这两种持久化方式,同时理解这种保存数据的思路,应用于自己的系
统设计中。
- 持久化的配置
- RDB与AOF持久化的工作原理
- 如何从持久化中恢复数据
- 关于性能与实践建议
持久化的配置
为了使用持久化的功能,我们需要先知道该如何开启持久化的功能。
RDB的持久化配置
# 时间策略
save 900 1
save 300 10
save 60 10000
# 文件名称
dbfilename dump.rdb
# 文件保存路径
dir /home/work/app/redis/data/
# 如果持久化出错,主进程是否停止写入
stop-writes-on-bgsave-error yes
# 是否压缩
rdbcompression yes
# 导入时是否检查
rdbchecksum yes配置其实非常简单,这里说一下持久化的时间策略具体是什么意思。
save 900 1 表示900s内如果有1条是写入命令,就触发产生一次快照,可以理解为就进行一次备份
save 300 10 表示300s内有10条写入,就产生快照下面的类似,那么为什么需要配置这么多条规则呢?因为Redis每个时段的读写请求肯定不是均衡的,为
了平衡性能与数据安全,我们可以自由定制什么情况下触发备份。所以这里就是根据自身Redis写入情况
来进行合理配置。 stop-writes-on-bgsave-error yes 这个配置也是非常重要的一项配置,这是当备
份进程出错时,主进程就停止接受新的写入操作,是为了保护持久化的数据一致性问题。如果自己的业
务有完善的监控系统,可以禁止此项配置, 否则请开启。 关于压缩的配置 rdbcompression yes ,
建议没有必要开启,毕竟Redis本身就属于CPU密集型服务器,再开启压缩会带来更多的CPU消耗,相比
硬盘成本,CPU更值钱。 当然如果你想要禁用RDB配置,也是非常容易的,只需要在save的最后一行写
上: save ""
RDB 配置详解与生产建议
# ====== 完整的 RDB 持久化配置 ======
# redis.conf
# --- 触发规则 ---
# 格式:save <seconds> <changes>
# 表示在 <seconds> 秒内至少有 <changes> 次修改则触发 bgsave
save 900 1 # 15分钟内至少1次修改 -> 适合低频写入场景
save 300 10 # 5分钟内至少10次修改
save 60 10000 # 1分钟内至少10000次修改 -> 适合高频写入场景
# save "" # 禁用 RDB 持久化
# --- 文件配置 ---
dbfilename dump.rdb # RDB 文件名
dir /var/lib/redis/ # 文件保存目录(RDB 和 AOF 共享此配置)
# --- 控制选项 ---
stop-writes-on-bgsave-error yes # bgsave 失败时停止写入(建议开启)
rdbcompression yes # 使用 LZF 压缩 RDB 文件(建议开启)
rdbchecksum yes # 使用 CRC64 校验(建议开启)
# --- 低级别配置(通常不需要修改) ---
# rdb-del-sync-files no # 无磁盘复制时不删除临时文件
# rdb-save-incremental-fsync yes # 增量式 fsync 减少延迟
# ====== 生产环境 save 策略建议 ======
# 根据业务场景选择不同的策略:
# 方案 1:高安全性(数据几乎不丢)
save 300 1
save 60 100
# 方案 2:高性能(允许丢失较多数据)
save 3600 1
save 300 100
save 60 10000
# 方案 3:中等平衡(推荐)
save 900 1
save 300 10
save 60 10000
# ====== 手动触发 RDB 快照 ======
# 在 redis-cli 中执行
SAVE # 同步保存,阻塞主进程(禁止在生产环境使用)
BGSAVE # 后台保存,fork 子进程(推荐)
LASTSAVE # 查看最后一次成功 RDB 的时间戳
# 在 Shell 中执行
redis-cli BGSAVE
redis-cli LASTSAVE
# 验证 RDB 文件
redis-cli --rdb /tmp/check.rdb
# 或使用 redis-check-rdb 工具
redis-check-rdb /var/lib/redis/dump.rdbAOF的配置
# 是否开启aof
appendonly yes
# 文件名称
appendfilename "appendonly.aof"
# 同步方式
appendfsync everysec
# aof重写期间是否同步
no-appendfsync-on-rewrite no
# 重写触发配置
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
# 加载aof时如果有错如何处理
aof-load-truncated yes
# 文件重写策略
aof-rewrite-incremental-fsync yes还是重点解释一些关键的配置: appendfsync everysec 它其实有三种模式:
always :把每个写命令都立即同步到aof,很慢,但是很安全 everysec :每秒同步一次,是折中方
案 no :redis不处理交给OS来处理,非常快,但是也最不安全
一般情况下都采用 everysec 配置,这样可以兼顾速度与安全,最多损失1s的数据。 aof-loadtruncated yes 如果该配置启用,在加载时发现aof尾部不正确是,会向客户端写入一个log,但是会
继续执行,如果设置为 no ,发现错误就会停止,必须修复后才能重新加载。
AOF 配置详解与生产建议
# ====== 完整的 AOF 持久化配置 ======
# redis.conf
# --- 基本配置 ---
appendonly yes # 开启 AOF 持久化
appendfilename "appendonly.aof" # AOF 文件名
appenddirname "appendonlydir" # AOF 文件目录(Redis 7.0+,使用多文件格式)
# --- 同步策略 ---
# always : 每次写入都 fsync,最安全但最慢(约降低 50% 性能)
# everysec : 每秒 fsync 一次,最多丢失 1s 数据(推荐)
# no : 由操作系统决定何时 fsync,最快但最不安全
appendfsync everysec
# --- 重写控制 ---
no-appendfsync-on-rewrite no # 重写期间是否停止 fsync(建议 no)
auto-aof-rewrite-percentage 100 # AOF 文件大小比上次重写后增长 100% 时触发重写
auto-aof-rewrite-min-size 64mb # AOF 文件最小 64MB 才触发重写
# --- 加载与恢复 ---
aof-load-truncated yes # 加载 AOF 时忽略文件末尾不完整的数据
aof-use-rdb-preamble yes # 开启 RDB-AOF 混合持久化(Redis 4.0+,强烈推荐)
# --- 文件同步 ---
aof-rewrite-incremental-fsync yes # 重写时增量 fsync,减少延迟
# ====== AOF 重写配置详解 ======
# AOF 文件会随着时间不断增长,重写机制用于压缩 AOF 文件
# 重写不是读取旧 AOF 文件,而是直接从内存中读取当前数据生成命令
# 手动触发重写
BGREWRITEAOF
# 自动重写条件(同时满足以下两个条件才触发):
# 1. AOF 文件大小 >= auto-aof-rewrite-min-size
# 2. AOF 文件大小 >= (上次重写后大小 * (1 + auto-aof-rewrite-percentage/100))
# 示例:
# auto-aof-rewrite-percentage 100
# auto-aof-rewrite-min-size 64mb
# 如果上次重写后 AOF 文件为 64MB,则下次在 128MB 时触发重写
# 重写后如果变为 50MB,则下次在 100MB 时触发重写
# ====== RDB-AOF 混合持久化(Redis 4.0+) ======
# 开启后,AOF 重写时会先写入 RDB 格式的快照
# 然后在末尾追加增量的 AOF 命令
# 这样既保持了 AOF 的数据完整性,又利用了 RDB 的快速加载优势
# 加载速度比纯 AOF 快 5-10 倍
# 开启混合持久化
aof-use-rdb-preamble yes
# 验证混合持久化是否生效
# 查看重写后的 AOF 文件头部
# 如果看到 REDIS0009 等二进制开头,说明包含 RDB 格式
hexdump -C /var/lib/redis/appendonly.aof | head -5
# ====== AOF 文件修复 ======
# 如果 AOF 文件损坏,Redis 无法启动
# 使用 redis-check-aof 工具修复
redis-check-aof --fix /var/lib/redis/appendonly.aof
# 只检查不修复
redis-check-aof /var/lib/redis/appendonly.aof
# 修复步骤:
# 1. 停止 Redis
# 2. 备份损坏的 AOF 文件
# 3. 执行修复
# 4. 手动检查修复后的文件
# 5. 启动 Redis工作原理
关于原理部分,我们主要来看RDB与AOF是如何完成持久化的,他们的过程是如何。
在介绍原理之前先说下Redis内部的定时任务机制,定时任务执行的频率可以在配置文件中通过 hz 10 来
设置(这个配置表示1s内执行10次,也就是每100ms触发一次定时任务)。该值最大能够设置为:500,
但是不建议超过:100,因为值越大说明执行频率越频繁越高,这会带来CPU的更多消耗,从而影响主进
程读写性能。
定时任务使用的是Redis自己实现的 TimeEvent,它会定时去调用一些命令完成定时任务,这些任务可能
会阻塞主进程导致Redis性能下降。因此我们在配置Redis时,一定要整体考虑一些会触发定时任务的配
置,根据实际情况进行调整。
RDB的原理
在Redis中RDB持久化的触发分为两种:自己手动触发与Redis定时触发。
针对RDB方式的持久化,手动触发可以使用:
save :会阻塞当前Redis服务器,直到持久化完成,线上应该禁止使用。 bgsave :该触发方式会fork
一个子进程,由子进程负责持久化过程,因此阻塞只会发生在fork子进程的时候。
而自动触发的场景主要是有以下几点:
- 根据我们的 save m n 配置规则自动触发;
- 从节点全量复制时,主节点发送rdb文件给从节点完成复制操作,主节点会触发 bgsave ;
- 执行 debug reload 时;
- 执行 shutdown 时,如果没有开启aof,也会触发。
由于 save 基本不会被使用到,我们重点看看 bgsave 这个命令是如何完成RDB的持久化的。
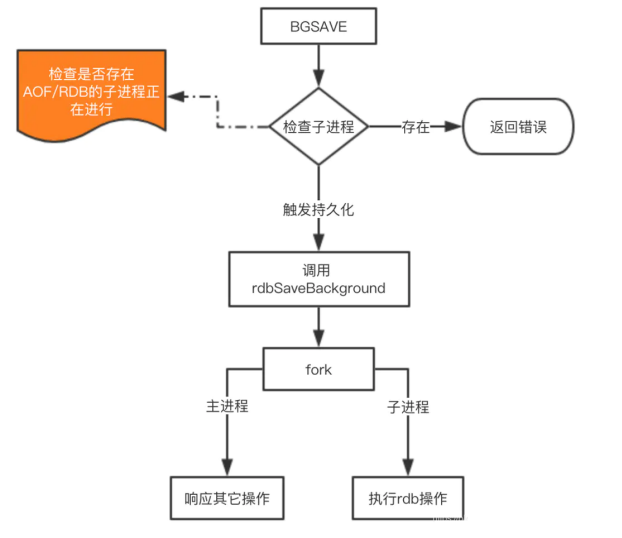
这里注意的是 fork 操作会阻塞,导致 Redis 读写性能下降。我们可以控制单个 Redis 实例的最大内
存,来尽可能降低 Redis 在 fork 时的事件消耗。以及上面提到的自动触发的频率减少 fork 次数,或
者使用手动触发,根据自己的机制来完成持久化。
RDB 原理详解
# ====== RDB 持久化流程详解 ======
# bgsave 命令的完整执行流程:
#
# 1. 主进程检查是否已有子进程在执行 bgsave
# - 如果有,则直接返回
# 2. 主进程 fork() 创建子进程
# - fork 操作是阻塞的,耗时与内存大小成正比
# - Linux 使用 COW(Copy On Write)机制
# - fork 后子进程共享父进程的内存页
# 3. 子进程将内存数据写入 RDB 临时文件
# - 遍历所有数据库
# - 将每个键值对序列化为 RDB 格式
# - 写入临时文件 dump.rdb.tmp-<pid>
# 4. 子进程完成写入后发送信号给主进程
# 5. 主进程收到信号后将临时文件 rename 为 dump.rdb
# - rename 是原子操作
# 6. 子进程退出
# ====== fork 阻塞问题 ======
# fork 阻塞时间 ≈ 内存大小 / 内存拷贝速度
# 通常 10GB 内存 fork 耗时约 100-200ms
# 查看上一次 fork 耗时(微秒)
redis-cli INFO stats | grep latest_fork_usec
# latest_fork_usec:312 # 表示 fork 耗时 312 微秒
# 优化 fork 性能的方法:
# 1. 控制 Redis 实例内存大小(建议单实例不超过 10GB)
# 2. 避免使用 Linux 的透明大页(THP)
# echo never > /sys/kernel/mm/transparent_hugepage/enabled
# 3. 使用合适的 save 配置减少 fork 频率
# 4. 将 Redis 绑定到 NUMA 节点
# ====== COW(写时复制)机制 ======
# fork 后,父子进程共享相同的物理内存页
# 当父进程修改某个内存页时,操作系统才会复制该页
# 因此 fork 后如果有大量写入,COW 会产生大量内存页复制
# 这就是为什么 bgsave 期间内存使用会短暂增加的原因
# 查看 COW 相关统计
redis-cli INFO memory | grep used_memory_human
redis-cli INFO persistence | grep rdb_
# ====== RDB 文件格式 ======
# RDB 文件是一个二进制格式文件,结构如下:
#
# +---------------------+
# | REDIS | 魔数(5 字节)
# +---------------------+
# | 版本号 | RDB 版本(4 字节)
# +---------------------+
# | 辅助字段 | Redis 版本、创建时间等
# +---------------------+
# | 数据库 0 | SELECTDB + 键值对数据
# +---------------------+
# | 数据库 1 | SELECTDB + 键值对数据
# +---------------------+
# | ... |
# +---------------------+
# | EOF | 结束标记(9 字节)
# +---------------------+
# | CRC64 | 校验和(8 字节)
# +---------------------+
# 检查 RDB 文件完整性
redis-check-rdb /var/lib/redis/dump.rdbAOF的原理
AOF的整个流程大体来看可以分为两步,一步是命令的实时写入(如果是 appendfsync everysec 配
置,会有1s损耗),第二步是对aof文件的重写。
对于增量追加到文件这一步主要的流程是:命令写入=》追加到aof_buf =》同步到aof磁盘。那么这里为
什么要先写入buf在同步到磁盘呢?如果实时写入磁盘会带来非常高的磁盘IO,影响整体性能。
aof重写是为了减少aof文件的大小,可以手动或者自动触发,关于自动触发的规则请看上面配置部分。
fork的操作也是发生在重写这一步,也是这里会对主进程产生阻塞。
手动触发: bgrewriteaof ,自动触发 就是根据配置规则来触发,当然自动触发的整体时间还跟Redis
的定时任务频率有关系。
下面来看看重写的一个流程图:
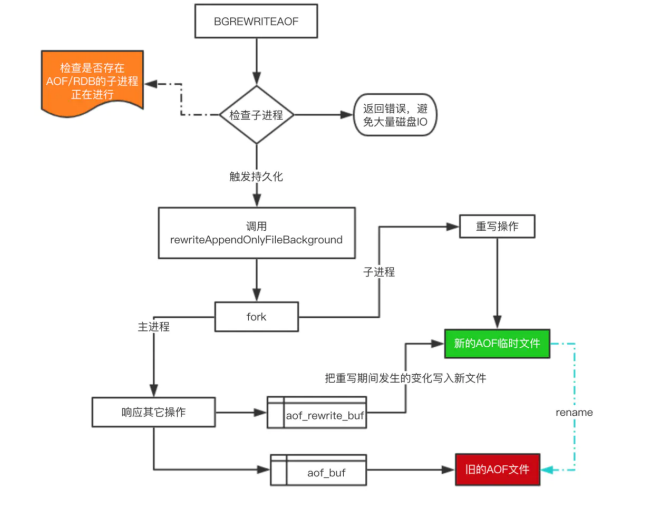
对于上图有四个关键点补充一下:
- 在重写期间,由于主进程依然在响应命令,为了保证最终备份的完整性;因此它依然会写入旧的
AOF file中,如果重写失败,能够保证数据不丢失。 - 为了把重写期间响应的写入信息也写入到新的文件中,因此也会为子进程保留一个buf,防止新写
的file丢失数据。 - 重写是直接把当前内存的数据生成对应命令,并不需要读取老的AOF文件进行分析、命令合并。
- AOF文件直接采用的文本协议,主要是兼容性好、追加方便、可读性高可认为修改修复。
不论是RDB还是AOF都是先写入一个临时文件,然后通过 rename 完成文件的替换工作。
AOF 原理详解
# ====== AOF 写入流程详解 ======
# 命令写入的完整流程:
#
# 1. 客户端发送写命令(SET, HSET, LPUSH 等)
# 2. Redis 将命令追加到 AOF 缓冲区(aof_buf)
# 3. 根据 appendfsync 策略,决定何时将缓冲区内容写入 AOF 文件
#
# 三种同步策略的详细说明:
#
# always:
# - 每次写入 aof_buf 后立即调用 fsync
# - 优点:数据最安全,最多丢失一个命令
# - 缺点:性能最差,fsync 是磁盘 IO 操作
# - 适用:金融交易等对数据安全要求极高的场景
#
# everysec:
# - 每秒调用一次 fsync
# - Redis 内部有一个后台线程,每秒调用 fsync
# - 如果 fsync 失败,Redis 会记录日志但继续运行
# - 优点:兼顾性能和安全,最多丢失 1 秒数据
# - 缺点:极端情况下可能丢失超过 1 秒数据
# - 适用:绝大多数生产环境(推荐)
#
# no:
# - 不主动调用 fsync,由操作系统决定何时写入磁盘
# - 操作系统通常每 30 秒 sync 一次
# - 优点:性能最好
# - 缺点:可能丢失 30 秒数据
# - 适用:缓存场景,数据丢失可接受
# ====== AOF 重写流程详解 ======
# 重写的目的:压缩 AOF 文件大小
# 例如:对同一个 key 执行了 100 次 SET,AOF 文件会记录 100 条命令
# 重写后只保留最后一条 SET 命令
# AOF 重写流程(bgrewriteaof):
#
# 1. 主进程 fork 子进程
# 2. 子进程遍历当前内存数据,生成新的 AOF 命令
# - 不读取旧 AOF 文件
# - 直接从内存读取最新数据
# 3. 子进程将新命令写入临时文件(AOF 重写缓冲区)
# 4. 在重写期间,主进程继续处理客户端命令
# - 新的写命令同时写入:
# a. 旧的 AOF 文件(保证数据安全)
# b. AOF 重写缓冲区(保证新文件包含所有数据)
# 5. 子进程完成写入后,主进程将重写缓冲区的内容追加到新文件
# 6. 主进程 rename 新文件替换旧 AOF 文件
# 查看 AOF 重写相关信息
redis-cli INFO persistence | grep aof_
# ====== AOF 缓冲区与刷盘机制 ======
# Redis 使用了三个缓冲区来处理 AOF 写入:
#
# 1. aof_buf(主进程缓冲区)
# - 所有写命令先写入此处
# - 每次 beforeSleep 时刷入 AOF 文件
#
# 2. AOF 重写缓冲区
# - AOF 重写期间使用
# - 记录重写期间的新增写命令
# - 重写完成后追加到新 AOF 文件
#
# 3. OS Page Cache
# - write() 只写入 Page Cache
# - fsync() 才真正写入磁盘
# ====== AOF 文件格式 ======
# AOF 文件使用 RESP(Redis Serialization Protocol)格式
# 每条命令都是纯文本,可直接阅读和手动编辑
#
# 示例 AOF 文件内容:
# *3 # 命令有 3 个参数
# $3 # 第一个参数长度 3
# SET # 第一个参数:SET
# $5 # 第二个参数长度 5
# hello # 第二个参数:hello
# $5 # 第三个参数长度 5
# world # 第三个参数:world
# 查看 AOF 文件内容
head -20 /var/lib/redis/appendonly.aof从持久化中恢复数据
数据的备份、持久化做完了,我们如何从这些持久化文件中恢复数据呢?如果一台服务器上有既有RDB
文件,又有AOF文件,该加载谁呢?
其实想要从这些文件中恢复数据,只需要重新启动Redis即可。我们还是通过图来了解这个流程: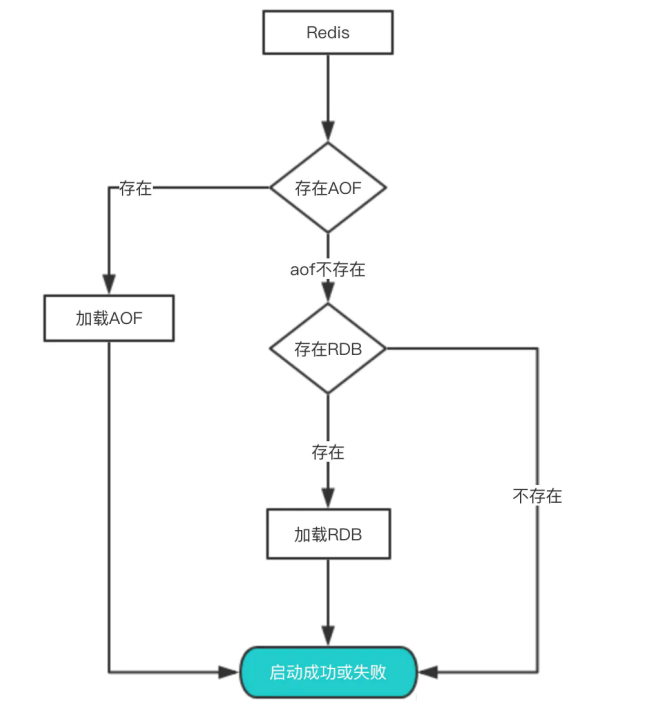
启动时会先检查AOF文件是否存在,如果不存在就尝试加载RDB。那么为什么会优先加载AOF呢?因为
AOF保存的数据更完整,通过上面的分析我们知道AOF基本上最多损失1s的数据。
数据恢复详解
# ====== Redis 启动时的数据恢复流程 ======
#
# 1. 检查是否开启了 AOF(appendonly yes)
# - 如果开启了,优先加载 AOF 文件
# - 如果 AOF 文件不存在或为空,回退到 RDB
# 2. 如果没有开启 AOF,加载 RDB 文件
# 3. 如果两者都不存在,Redis 以空数据库启动
# ====== 手动恢复数据 ======
# 场景 1:使用 RDB 文件恢复
# 1. 停止 Redis
systemctl stop redis
# 2. 备份当前数据
cp /var/lib/redis/dump.rdb /var/lib/redis/dump.rdb.bak
# 3. 将备份的 RDB 文件复制到数据目录
cp /backup/redis/dump_20240101.rdb /var/lib/redis/dump.rdb
# 4. 确保 AOF 关闭(如果开启了 AOF,Redis 会优先加载 AOF)
# 临时禁用 AOF 的方法:将 appendonly.aof 临时移走
mv /var/lib/redis/appendonly.aof /var/lib/redis/appendonly.aof.bak
# 5. 启动 Redis
systemctl start redis
# 6. 验证数据
redis-cli DBSIZE
redis-cli KEYS '*' | head -20
# 场景 2:使用 AOF 文件恢复
# 1. 停止 Redis
systemctl stop redis
# 2. 备份当前文件
cp /var/lib/redis/appendonly.aof /var/lib/redis/appendonly.aof.bak
# 3. 将备份的 AOF 文件复制到数据目录
cp /backup/redis/appendonly_20240101.aof /var/lib/redis/appendonly.aof
# 4. 检查 AOF 文件是否完整
redis-check-aof /var/lib/redis/appendonly.aof
# 5. 如果文件损坏,尝试修复
redis-check-aof --fix /var/lib/redis/appendonly.aof
# 6. 启动 Redis
systemctl start redis
# 场景 3:跨服务器迁移数据
# 方法 1:直接复制 RDB/AOF 文件
scp /var/lib/redis/dump.rdb user@target-server:/var/lib/redis/dump.rdb
# 方法 2:使用 redis-cli 迁移
# 在源服务器上:
redis-cli --rdb /tmp/dump.rdb
scp /tmp/dump.rdb user@target-server:/var/lib/redis/dump.rdb
# 方法 3:在线热迁移(不停机)
redis-cli --pipe target-server < dump.rdb
# 或使用 redis-shake 工具进行在线迁移
# ====== 恢复验证清单 ======
# 1. 检查数据量是否正确
redis-cli INFO keyspace
# 2. 检查内存使用是否正常
redis-cli INFO memory | grep used_memory_human
# 3. 检查客户端连接是否正常
redis-cli CLIENT LIST
# 4. 检查慢查询日志
redis-cli SLOWLOG GET 10
# 5. 检查持久化状态
redis-cli INFO persistence性能与实践
通过上面的分析,我们都知道RDB的快照、AOF的重写都需要fork,这是一个重量级操作,会对Redis造
成阻塞。因此为了不影响Redis主进程响应,我们需要尽可能降低阻塞。
- 降低fork的频率,比如可以手动来触发RDB生成快照、与AOF重写;
- 控制Redis最大使用内存,防止fork耗时过长;
- 使用更牛逼的硬件;
- 合理配置Linux的内存分配策略,避免因为物理内存不足导致fork失败。
在线上我们到底该怎么做?我提供一些自己的实践经验。
- 如果Redis中的数据并不是特别敏感或者可以通过其它方式重写生成数据,可以关闭持久化,如果
丢失数据可以通过其它途径补回; - 自己制定策略定期检查Redis的情况,然后可以手动触发备份、重写数据;
- 单机如果部署多个实例,要防止多个机器同时运行持久化、重写操作,防止出现内存、CPU、IO资
源竞争,让持久化变为串行; - 可以加入主从机器,利用一台从机器进行备份处理,其它机器正常响应客户端的命令; RDB持久化
与 - AOF持久化可以同时存在,配合使用。
性能优化实践详解
# ====== fork 优化 ======
# 1. 控制 Redis 实例内存大小
# 建议单实例内存不超过物理内存的 50%
# 最大不超过 10GB(fork 耗时可接受范围)
# 2. 禁用透明大页(THP)
echo never > /sys/kernel/mm/transparent_hugepage/enabled
# 持久化配置,加入 /etc/rc.local
echo 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' >> /etc/rc.local
chmod +x /etc/rc.local
# 3. 设置 vm.overcommit_memory=1
echo 1 > /proc/sys/vm/overcommit_memory
# 持久化配置
echo 'vm.overcommit_memory = 1' >> /etc/sysctl.conf
sysctl -p
# ====== 磁盘 IO 优化 ======
# 1. 使用高性能磁盘(SSD)
# 2. 将 AOF 文件和 RDB 文件放在不同的磁盘上
# 3. 挂载时使用 noatime 选项减少 IO
# /dev/sdb1 /var/lib/redis ext4 noatime 0 2
# ====== 混合持久化配置(Redis 4.0+) ======
# 同时使用 RDB 和 AOF,取长补短
# 在 redis.conf 中配置:
appendonly yes
aof-use-rdb-preamble yes
# 这种配置下:
# - AOF 重写时先写入 RDB 格式快照(体积小,加载快)
# - 然后追加增量 AOF 命令(保证数据完整性)
# - 恢复时先加载 RDB 部分(快速),再回放 AOF 命令
# ====== RDB 和 AOF 的选择建议 ======
#
# 纯缓存场景(数据丢失可接受):
# - 关闭持久化,或仅保留 RDB
# - appendonly no
#
# 一般业务场景(允许少量数据丢失):
# - 开启 AOF + everysec
# - appendonly yes, appendfsync everysec
#
# 重要数据场景(数据安全要求高):
# - AOF + everysec + RDB 混合持久化
# - appendonly yes, aof-use-rdb-preamble yes
#
# 金融/交易场景(数据不能丢失):
# - AOF + always
# - appendonly yes, appendfsync always
# - 搭配主从复制和多副本
# ====== 主从环境下的持久化策略 ======
# 最佳实践:
# - 主节点:关闭持久化(或仅开启 AOF)
# - 从节点:开启 RDB + AOF 混合持久化
# - 定期从从节点复制备份文件到远程存储
#
# 配置示例(主节点):
# save "" # 禁用 RDB
# appendonly no # 禁用 AOF
#
# 配置示例(从节点):
# save 900 1 # 开启 RDB
# appendonly yes # 开启 AOF
# aof-use-rdb-preamble yes # 混合持久化
# ====== 自动备份脚本 ======
#!/bin/bash
# redis_backup.sh - Redis 自动备份脚本
set -euo pipefail
REDIS_HOST="127.0.0.1"
REDIS_PORT="6379"
REDIS_PASS="your_password"
BACKUP_DIR="/backup/redis"
RETENTION_DAYS=7
DATE=$(date +%Y%m%d_%H%M%S)
LOG_FILE="/var/log/redis/backup.log"
log() {
echo "[$(date '+%Y-%m-%d %H:%M:%S')] $*" >> "$LOG_FILE"
}
mkdir -p "$BACKUP_DIR"
# 触发 RDB 快照
log "Triggering BGSAVE..."
redis-cli -h "$REDIS_HOST" -p "$REDIS_PORT" -a "$REDIS_PASS" BGSAVE
# 等待 BGSAVE 完成
WAIT=0
MAX_WAIT=60
while [ $WAIT -lt $MAX_WAIT ]; do
if redis-cli -h "$REDIS_HOST" -p "$REDIS_PORT" -a "$REDIS_PASS" LASTSAVE | grep -q $(date +%s); then
break
fi
sleep 1
WAIT=$((WAIT + 1))
done
if [ $WAIT -ge $MAX_WAIT ]; then
log "ERROR: BGSAVE timeout after ${MAX_WAIT}s"
exit 1
fi
# 复制 RDB 文件到备份目录
cp /var/lib/redis/dump.rdb "${BACKUP_DIR}/dump_${DATE}.rdb"
# 如果开启了 AOF,也备份 AOF 文件
if [ -f "/var/lib/redis/appendonly.aof" ]; then
cp /var/lib/redis/appendonly.aof "${BACKUP_DIR}/appendonly_${DATE}.aof"
fi
# 压缩备份
gzip "${BACKUP_DIR}/dump_${DATE}.rdb"
[ -f "${BACKUP_DIR}/appendonly_${DATE}.aof" ] && gzip "${BACKUP_DIR}/appendonly_${DATE}.aof"
# 清理过期备份
find "$BACKUP_DIR" -name "*.gz" -mtime +$RETENTION_DAYS -delete
log "Backup completed: dump_${DATE}.rdb.gz"持久化监控与告警
# ====== 持久化状态监控 ======
# 查看 RDB 状态
redis-cli INFO persistence | grep rdb_
# rdb_bgsave_in_progress:0 # 是否正在 bgsave
# rdb_last_bgsave_status:ok # 上次 bgsave 是否成功
# rdb_last_bgsave_time_sec:0 # 上次 bgsave 耗时(秒)
# rdb_last_bgsave_timestamp:1700000000 # 上次 bgsave 时间戳
# rdb_changes_since_last_save:0 # 上次 save 后的修改次数
# 查看 AOF 状态
redis-cli INFO persistence | grep aof_
# aof_enabled:1 # AOF 是否开启
# aof_rewrite_in_progress:0 # 是否正在重写
# aof_last_rewrite_time_sec:0 # 上次重写耗时(秒)
# aof_current_size:0 # 当前 AOF 文件大小
# aof_base_size:0 # 上次重写后的大小
# aof_pending_rewrite:0 # 是否有待执行的重写
# aof_buffer_length:0 # AOF 缓冲区大小
# aof_rewrite_buffer_length:0 # AOF 重写缓冲区大小
# aof_last_bgrewrite_status:ok # 上次重写是否成功
# aof_last_write_status:ok # 上次写入是否成功
# 查看 fork 耗时
redis-cli INFO stats | grep latest_fork_usec
# latest_fork_usec:312 # fork 耗时(微秒)
# ====== 监控脚本示例 ======
#!/bin/bash
# redis_persistence_monitor.sh
REDIS_CLI="redis-cli -h 127.0.0.1 -p 6379"
# 检查 RDB 状态
rdb_bgsave=$($REDIS_CLI INFO persistence | grep rdb_bgsave_in_progress | cut -d: -f2 | tr -d '\r')
rdb_status=$($REDIS_CLI INFO persistence | grep rdb_last_bgsave_status | cut -d: -f2 | tr -d '\r')
rdb_changes=$($REDIS_CLI INFO persistence | grep rdb_changes_since_last_save | cut -d: -f2 | tr -d '\r')
fork_time=$($REDIS_CLI INFO stats | grep latest_fork_usec | cut -d: -f2 | tr -d '\r')
echo "=== RDB Status ==="
echo "bgsave in progress: $rdb_bgsave"
echo "last bgsave status: $rdb_status"
echo "changes since last save: $rdb_changes"
echo "last fork time (us): $fork_time"
# 检查 AOF 状态
aof_enabled=$($REDIS_CLI INFO persistence | grep aof_enabled | cut -d: -f2 | tr -d '\r')
aof_rewrite=$($REDIS_CLI INFO persistence | grep aof_rewrite_in_progress | cut -d: -f2 | tr -d '\r')
aof_size=$($REDIS_CLI INFO persistence | grep aof_current_size | cut -d: -f2 | tr -d '\r')
aof_status=$($REDIS_CLI INFO persistence | grep aof_last_write_status | cut -d: -f2 | tr -d '\r')
echo "=== AOF Status ==="
echo "aof enabled: $aof_enabled"
echo "rewrite in progress: $aof_rewrite"
echo "aof file size: $aof_size"
echo "last write status: $aof_status"
# 告警条件
if [ "$rdb_status" != "ok" ]; then
echo "[ALERT] RDB bgsave failed!"
fi
if [ "$aof_enabled" = "1" ] && [ "$aof_status" != "ok" ]; then
echo "[ALERT] AOF write failed!"
fi
if [ "$fork_time" -gt 1000000 ]; then
echo "[ALERT] Fork time too high: ${fork_time}us (>1s)"
fi
# ====== Zabbix / Prometheus 监控指标 ======
# 关键监控指标:
# 1. redis_last_save_timestamp_seconds - 最后一次 save 时间
# 2. redis_rdb_changes_since_last_save - save 后的修改次数
# 3. redis_aof_enabled - AOF 是否开启
# 4. redis_aof_current_size_bytes - AOF 文件大小
# 5. redis_latest_fork_usec - fork 耗时
# 6. redis_aof_buffer_length - AOF 缓冲区长度关键知识点
- 部署类主题的核心不是"装成功",而是"稳定运行、可排障、可回滚"。
- 同一个服务通常至少要关注版本、目录、端口、权限、数据、日志和备份。
- Linux 问题经常跨越系统层、网络层、服务层和应用层。
- 缓存与开关类主题都在处理"配置/数据与运行时行为之间的解耦"。
- RDB 是全量快照,恢复速度快但可能丢失较多数据。
- AOF 是增量日志,数据安全性高但文件体积大,恢复慢。
- 混合持久化(Redis 4.0+)结合两者优点,推荐开启。
- fork 操作是持久化性能瓶颈的关键,需控制实例内存大小。
- 生产环境建议 appendfsync 设为 everysec,兼顾性能和安全。
项目落地视角
- 把安装步骤补成可重复执行的清单,必要时写成脚本或配置文件。
- 把配置目录、数据目录、日志目录和挂载点明确拆开。
- 上线前检查防火墙、SELinux、时区、磁盘、系统服务和健康检查。
- 明确 Key 设计、过期策略、回源逻辑和降级方案。
- 根据数据重要性选择合适的持久化策略。
- 建立自动备份和恢复演练机制。
常见误区
- 使用 latest 或未固定版本,导致环境不可复现。
- 只验证启动成功,不验证持久化、开机自启和故障恢复。
- 遇到问题先改配置而不是先看日志和依赖链路。
- 只加缓存,不设计失效与一致性策略。
- 在生产环境使用 SAVE 命令(会阻塞主进程)。
- 忽略 fork 阻塞对 Redis 性能的影响。
- 不监控 AOF 文件大小增长,导致磁盘写满。
- AOF 文件损坏后不修复直接重启 Redis。
进阶路线
- 继续补齐 systemd、性能监控、安全加固和备份恢复。
- 把单机操作升级成 Docker、Kubernetes 或 IaC 方案。
- 建立标准化运维手册,包括巡检、扩容、回滚和灾备演练。
- 继续补齐多级缓存、缓存预热、分布式缓存治理和旗标管理平台。
- 学习 Redis 7.0 的多部分 AOF(appendonlydir)机制。
- 研究 Redis Cluster 模式下的持久化策略。
适用场景
- 当你准备把《Redis 6.x 持久化》真正落到项目里时,最适合先在一个独立模块或最小样例里验证关键路径。
- 适合单机环境初始化、中间件快速搭建、测试环境验证和生产部署前准备。
- 当服务稳定性依赖端口、权限、目录、网络和系统参数时,这类主题会直接影响成败。
落地建议
- 固定版本号与镜像标签,避免"latest"带来的不可预期变化。
- 把配置、数据、日志目录拆开管理,并记录恢复步骤。
- 上线前确认端口、防火墙、SELinux、时区和磁盘空间。
- 推荐使用混合持久化(aof-use-rdb-preamble yes)。
- 定期检查 AOF 文件大小,设置合理的重写阈值。
- 建立持久化监控告警(bgsave 失败、fork 耗时过长等)。
排错清单
- 先查 systemctl、容器日志和应用日志,确认失败发生在哪一层。
- 检查端口占用、目录权限、挂载路径和网络连通性。
- 如果是新环境问题,优先对比与已知正常环境的差异。
- 检查 Redis 日志中是否有 BGSAVE 或 AOF 重写相关错误。
- 使用 redis-check-rdb 和 redis-check-aof 检查文件完整性。
- 检查磁盘空间是否充足(df -h)。
- 检查 vm.overcommit_memory 是否设置为 1。
复盘问题
- 如果把《Redis 6.x 持久化》放进你的当前项目,最先要验证的输入、输出和失败路径分别是什么?
- 《Redis 6.x 持久化》最容易在什么规模、什么边界条件下暴露问题?你会用什么指标或日志去确认?
- 相比默认实现或替代方案,采用《Redis 6.x 持久化》最大的收益和代价分别是什么?
- 如果 Redis 实例内存达到 20GB,如何优化持久化性能?